
This article is the first in a series of articles on Information in Manufacturing by MESA's Smart Manufacturing Working Group.
Ever heard of the phrase “data is the new oil?” It’s a common saying these days, and it’s true. Data has become increasingly important in today's manufacturing world, but what exactly is it?
This first article delineates a common understanding of manufacturing data, identifies types of such data, the various sources of data, the mechanisms for exchange of data, the technologies to capture data and the various methods to organize and store manufacturing data.
1.0 Manufacturing Data
Most people who work in the manufacturing sector relate to manufacturing data either from an IT perspective, an OT perspective or a business perspective. But what they require is a common industry perspective that understands how such data is enabling Smart Manufacturing initiatives and reshaping the industrial ecosystem for better collaboration and communication. In this article (and in the context of Smart Manufacturing), we will delineate a common understanding of manufacturing data and elucidate the various data types, data sources, methods of data exchange, data capture & ingestion technologies, and different ways data can be persisted and organized to seek business value.
1.1 What is manufacturing data?
Manufacturing data refers to the data generated during the process of manufacturing goods that is collected manually or by using sensors, automation systems and other technologies. Manufacturing data helps monitor and optimize the production process, improve quality control and identify opportunities for cost savings and efficiency improvements. It can also track and trace the flow of materials from the supply chain through product delivery, and support the development of new products.
Common manufacturing data types are:
- Production data: This can include information about the quantity and quality of goods produced, as well as the time required to produce them.
- Process data: This can include information about the various steps or stages involved in the manufacturing process, such as raw material inputs, intermediate products and finished goods.
- Product data: This can include the creation, modification and archival of all information produced that is related to a product.
- Equipment data: This can include information about the performance and maintenance of manufacturing equipment, such as machine utilization, downtime and maintenance schedules.
- Quality data: This can include information about the quality of the goods produced, such as measurements of dimensions, tolerances or other characteristics important for qualifying the end product.
- Financial data: This can include information about the costs associated with the manufacturing process, including labor costs, raw material costs and overhead costs.
- Facility & Environmental data: This can include information about the environmental impact of the manufacturing process, including emissions, waste generation and resource consumption.
- Supplier data: Data about warehousing, transportation and supplier of materials, their on-time performance and the quality record of their different ingredients, materials and parts.
- Audit and compliance data: Data from reports on prior internal and external procedural and regulatory compliance audits.
During the 1980s and 1990s, the growth of the internet and the proliferation of personal computers led to an explosion in the amount of digital data generated. This increase in data volume, along with the development of new technologies for storing and analyzing data, led to the creation of vast quantities of data and the eventual rise of the term "big data." Big data can encompass any type of large-scale dataset, but it generally refers to datasets that are a combination of large, complex and diverse structured and unstructured data. These datasets are unmanageable using traditional databases or analytics software. Storage of these datasets is typically in cloud computing environments, and easily accessible by multiple users simultaneously. From a business perspective, thoughtful analysis of big data can provide valuable insights into customer behavior, market trends and other information that enables better decision-making.
The 3 Vs of Data
As mentioned, raw data is just raw material. But with thoughtful processing and analysis, raw data transforms into valuable insights that objectively inform decisions instead of relying on guesswork. Getting value out of data is not a panacea. To derive maximum value, one must understand the inherent characteristics and relationships. Following are three such characteristics.
Volume
The first “V” refers to the sheer quantity of data collected by businesses. This includes all types of data, from structured data (i.e., easily searchable and organized) to unstructured data (may not have an obvious structure). As technology has become increasingly sophisticated, businesses have collected a wide variety of data points about their customers and operations—which means more opportunities for identifying patterns in customer behavior or uncovering new sources of revenue. As a result, large companies have been investing heavily in developing robust analytics capabilities that can digest large amounts of data.
Velocity
The second “V” refers to the speed of collecting and analyzing data. With traditional methods of analyzing data, it could take days or even weeks for insights to become available. But with big data tools like Hadoop, organizations can gain access to real-time insights in minutes or even seconds. This means making accurate decisions faster, which is crucial for a quick response to changing market conditions or customer needs.
Variety
The third “V” refers to the range of differing types of information collected and analyzed. The data may take various forms like Boolean, analog, images, videos, files or others. Some examples include customer demographics, buying behaviors, website activity, social media interactions, location-based information and machine-generated logs from sensors or devices. If interpreted correctly, this information provides valuable insights into customer behavior or operational performance. That is why companies desire robust analytics capabilities that enable them to convert this varied data into useful information that guides strategic decision-making.
In addition to these characteristics, there are two important attributes to consider when evaluating any sort of data, especially manufacturing data:
- Value: This indicates the importance of the data point in solving the problem at hand. In other words, is the data applicable for making a decision to solve a problem or pain point?
- Trustworthiness: This indicates if data is trustworthy for decision-making, collaboration or communication.
Manufacturing data can provide insight about which processes are working well and which need improvement. It can also gauge production efficiency and how much waste is produced. In short, it provides fact-based, granular information for reasoning and analysis to support timely decision-making or facilitate communication and collaboration about processes and products.
2.0 Characteristics of Manufacturing Data
There are three main levels of structure in how we store data that manufacturing systems create or use: Structured, Semi-Structured and Unstructured.
- Structured Data: This data is highly organized, which simplifies storage and retrieval, and most often follows a tabular format containing quantitative information. Because it follows a known structure, it is understandable by both machines and people. It maintains this format from its origin until its final storage destination. Some typical arrangements used in this context include time series, machine data, relational database (SQL data) and spatial data. Typically, this type of data helps to resolve key performance indicators (KPIs).
- Semi-Structured Data: This type of data, which is storable and retrievable for later analysis, does not conform to any rigid structure, but generally has a recognizable pattern. Its content is a mix of quantitative and qualitative data and most often requires interpretation before it is useful. Some typical examples are email, web-based content, XML and JSON, and may contain an aggregation of data from different sources like streaming data, batch data and environment data. Due to its structural flexibility, semi-structured data is free to evolve as needed and is more future-proof than structured data.
- Unstructured Data: This type of data does not conform to any one format or schema and can contain files and images, work instructions or standard operating procedures, and sometimes a mixed aggregation of structured and semi-structured data. Because of its inconsistent arrangement, this data is not machine readable and cannot be stored in a database except in whole form. For the data to be useful, one must first interpret it.
In addition to structure, manufacturing data will also differ by the frequency and detail by which collected: Discrete, Continuous or Batch.
- Discrete Data: Data that consists of distinct values or categories that have clear boundaries and spaces between them. Examples of discrete data include counts (whole number values), grades (A, B, C), enumeration sets (predefined meaning for numeric values) or Boolean values (true or false).
- Continuous Data: Data that can have unlimited range of values between two points on a time scale. Continuous data measures or trends something that can take on any value within a range, such as temperature or speed, with the ability to break down values into even smaller units of precision. For example, when measuring the temperature outside you could record it as 73 degrees Fahrenheit or 73.2 degrees Fahrenheit, depending on how precise you need your measurement to be.
- Batch Data: Data that consists of related information collected over time, such as customer orders or sales totals for a given period. It is important to note that data does not need to be collected at regular intervals; it simply needs to be aggregated to analyze it more easily and efficiently than as separate pieces of information from different sources.
One more way that manufacturing data can vary is by its relationship to time: Transactional, Real-Time or Streaming.
- Transactional Data: Data that is event-based and generated at a specific instance of time (relative to when the event occurs). An inherent benefit of this type of data is its relationship to an event. The event type naturally imparts useful context to the data, simplifying interpretation and analysis. Most often this contains a set of data, rather than just one value.
- Real-Time Data: This data, often called time-series because it includes a date-time stamp for each datum, is used for process control and to produce trend graphs, and has only one current value that changes with time. This data is inherently singular and constantly changing but sampling can produce a single snapshot value for any instance of time desired. Streaming data is a variant of real-time that strings together multiple snapshot values at a known interval.
3.0 Sources of Manufacturing Data
When consuming manufacturing data, it is helpful to understand the origins of that data, which can provide context that helps detangle the large and diverse data sets created along the path of the manufacturing lifecycle. Raw data is not useful without interpretation, but once interpreted, it is easier to fulfill needs or solve problems related to processing, analysis and reporting.
To understand potential sources, we need to first reference the ISA-95 model, also called the Purdue model, for understanding the data generated at the five levels shown here.
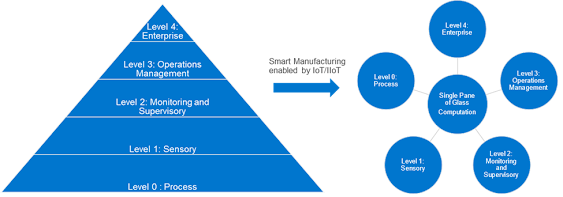
Figure 1: An illustration of the data generated at each ISA-95 level and how Smart Manufacturing leverages it
The data sources in a Smart Manufacturing environment have a single pane of glass access for computation instead of hierarchical access. A single pane of glass for computation provides a common access to data from all levels, and enables edge and cloud-computing based platforms.
Let us consider the data generated at these levels:
Level 0: The data sources at this level are mostly structured or unstructured and captured manually through spreadsheets, document templates or paper forms and later re-entered or uploaded to a higher-level system and focused on process data.
Level 1: The data sources here reflect the more automated OT data generators like sensors, cameras and OEM assets that store and forward structured data, and industrial PCs and gateways that aggregate data from multiple sources.
Levels 2-3: The data sources here can vary between levels 2 and level 3, depending on individual customer preferences. These systems of origin may also be post-processing OT data received from level 0 and level 1 and aggregating it with additional inputs from people and level 4 systems to generate new sets of data. The data here could include data related to recipes, material BOMs, quality specs, inventory, asset maintenance and production workforce. Typical systems include SCADA, MES, Environment Health and Safety, Lab Information Management Systems and Maintenance Management Systems.
Level 4: These data sources include data generated by ERP systems that include PLM, SCM and CRM data. Clearly, data origination can occur at all levels. Levels 0 to 3 generate approximately 90 percent of Operational Technology (OT) data (i.e., production-oriented data related to production processes, assets, material flow, product quality, etc.); the rest originates in level 4. Information Technology (IT) data related to product design, new product introduction, planning and scheduling, HR (business- IT and OT), customer information and supply chain activities primarily is generated at level 4.
4.0 Methods for Exchanging Manufacturing Data
Data exchange refers to the transfer of information between two or more systems and relates to both the process and protocol used for exchanging data. A simple example of data exchange would be a customer service representative entering a customer’s order into an online database, after which the data then is sent from one system (the online database) to another (the order fulfillment system).
There are three primary methods used for exchanging data: manual input, file transfer and programmatic (application programming interfaces (APIs), web services and standards-based communication). Let us look at each method in greater detail.
Manual Input - Manual input involves manually entering or copying information from one source into another. When using this method, there is risk of duplicate entries or errors, and it can be labor-intensive, especially if done on a large scale. This type of data, which usually ends up on local spreadsheets or databases, is not easily shared across the organization.
File Transfer - File transfer involves transferring files between computers or servers over the internet or other networks using software such as FTP, SFTP, SCP or others. File transfers are used to quickly and securely exchange large amounts of document-based data.
API & Web Services - APIs and web services allow applications to communicate with each other without having to manually enter information into each system. These methods often are used when there is a need for real-time communication between two systems or for automating tasks such as sending emails, creating reports, etc.
Data Exchange Standards – Standardized communication architectures supplement APIs and web services to provide a more complete programmatic option. Some popular examples are OPC UA, IPC-CFX, OAGIS and MIMOSA. OPC UA originated from and is closely linked to industrial automation, while the others are more generic and used for integrating business applications. OPC UA is the most mature and pervasive of these examples:
OPC UA: OPC is the interoperability standard for the secure and reliable exchange of data in the industrial automation space and in other industries. It is platform independent and ensures the seamless flow of information among devices from multiple vendors. The OPC Foundation [reference] is responsible for the development and maintenance of this standard, which is a series of specifications developed by industry vendors, end users and software developers. These specifications define the interface between clients and servers, as well as between servers and servers, including access to real-time data, monitoring of alarms and events, access to historical data and other applications.
When first released in 1996, the purpose of the standard was to abstract PLC-specific protocols (such as Modbus, Profibus, etc.) into a standardized interface, allowing HMI/SCADA systems to interface with a “middle man” who would convert generic OPC read/write requests into device-specific requests and vice-versa. As a result, an entire cottage industry of products emerged, allowing end users to implement systems using best-of-breed products all seamlessly interacting via OPC.
Initially, the OPC standard was restricted to the Windows operating system. As such, the acronym OPC was born from OLE-object linking and embedding for process control. These specifications, which are now known as OPC Classic, have enjoyed widespread adoption across multiple industries, including manufacturing, building automation, oil and gas, renewable energy and utilities, and others. With the introduction of service-oriented architectures in manufacturing systems came new challenges in security and data modeling. The OPC Foundation developed the OPC UA specifications to address these needs and at the same time provided a feature-rich technology open-platform architecture that was future-proof, scalable and extensible. Today the acronym OPC stands for Open Platform Communications.
In summary, the advantage of OPC is that it is an independent and flexible platform that provides data modeling across the entire manufacturing enterprise. Its standard/common interfaces make it amenable to integrate disparate systems such as Manufacturing Execution Systems (MES), Enterprise Resource Planning (ERP) systems, cloud platforms and databases. When used for Machine to Machine (M2M) communications between disparate controllers/vendors, OPC defines a common language for communicating between machines.
IPC-CFX: The Connected Factory Exchange (CFX) standard is a modern, IIoT message-based standard, originating in the electronics manufacturing sector. The design of CFX meets the increasingly complex demands of Smart Industry 4.0 manufacturing in a cost-effective way that completely avoids the need for software customization or middleware, eliminating deployment difficulties and delays. CFX consists of a single defined language, covering all aspects of manufacturing execution, including routing, planning, quality, materials, performance, recipe management, energy management and sustainability, predictive maintenance, machine learning, closed-loops and more. CFX offers true “plug and play” capability, with qualification of machines and devices provided by IPC. CFX uses the secure banking protocol, AMQP v1.0 that allows end-to-end encryption of messaging, so messages are directly “internet enabled,” uniquely supporting both message broadcasting and point-to-point control. CFX is rapidly becoming the standard of choice for major global OEM and EMS companies that include electronics manufacturing, and expanding into other discrete manufacturing areas. Gateways for PLC connection, as well as conversions from other data transport standards such as OPC-UA and MT-Connect, are seen. As well, the Raspberry Pi based IPC CFX Legacy Box provides an open-source “off the shelf” hardware and software DIY solution for the upgrade of non-Smart machine connections at a very low cost (typically sub $100). IPC also provides a comprehensive free to anyone SDK, that makes CFX easy to implement at a very low cost into existing devices, machines and software solutions. Updates to the CFX language are made roughly every six months, expanding the scope and reach of CFX by (free to join) industry consensus. For more information, visit www.ipc.org\ipc-cfx.
5.0 Technologies for Communication of Manufacturing Data
Radio Frequency Identification (RFID)
Radio frequency identification (RFID) is a technology that uses radio waves to identify objects or people. RFID tags typically are attached to items or people to identify them. The tags contain a unique identifier read by an RFID reader. This allows companies to track the movement of items or people in real-time. RFID is used widely in factories, warehouses, airports, hospitals, retail stores and more.
Near Field Communication (NFC)
Near field communication (NFC) is a technology that uses electromagnetic fields to enable two-way communication between two devices over short distances without the need for wires or cables. This makes it ideal for mobile payments and other applications where speed is of the essence. NFC is becoming increasingly popular in retail stores to make purchases more secure and convenient for customers.
Wi-Fi Technology
Wi-Fi (wireless fidelity) is a commonly used technology for capturing and transmitting data without wire. Wi-Fi-enabled IIoT sensors share data over short to medium ranges, and is therefore good for connecting multiple devices at scale. However, Wi-Fi has challenges due to interference in more complex environments, so not the most reliable.
Bluetooth Technology
Bluetooth technology is a well-known WLAN technology designed primarily for connecting wireless devices with each other over short distances, usually within 10 meters (30 feet). Bluetooth technology transmits both audio and video signals wirelessly between two compatible devices. Use cases on the plant floor include asset tracking, automatic data entry during quality inspections, location awareness applications, warehouse storage and retrieval applications, etc.
The Internet of Things (IoT)
The Internet of Things (IoT) is an emerging technology which interconnects physical objects locally or with internet-based networks. The IoT-connected objects gather and share data via internet protocols while using commonly understood, readily available and inexpensive hardware or wireless connections. By expanding and democratizing an ecosystem of smart devices, these devices work together more easily for a common purpose.
The Industrial Control & Automation sector uses a variety of protocols supporting numerous OEM vendors. Although OEM architectures are built to meet certain scalability and latency requirements of vendor-specific systems, they are now based on open standards and support a point to point, single direction source to multipoint target systems and bidirectional exchange between multiple sources and targets. There are underlying protocols to define how source and destination systems communicate and exchange data. Following is a list of commonly used protocols.
Profibus: Profibus (usually styled as PROFIBUS and referred to as Process Field Bus) is a standard for fieldbus communication in automation technology first promoted in 1989 by BMBF (German department of education and research), and then used by Siemens. Profibus is openly published as part of IEC 61158. https://www.profibus.com/
Profinet: Profinet (usually styled as PROFINET and referred to as Process Field Net) is an industry technical standard for data communication over the industrial Ethernet, and designed for collecting data from, and controlling equipment in, industrial systems. Its particular strength is delivering data under tight time constraints. Profibus & Profinet International, an umbrella organization headquartered in Karlsruhe, Germany, maintains and supports the standard. https://us.profinet.com/technology/profinet/
CAN: A Controller Area Network (CAN Bus) is a bus standard designed to allow microcontrollers and devices to communicate with each other's applications without a host computer. This message-based protocol, designed originally for multiplex electrical wiring within automobiles to save on copper, also is used in many other contexts. Development of the CAN bus started in 1983 at Robert Bosch GmbH. The official release of the protocol was in 1986 at the Society of Automotive Engineers (SAE) conference in Detroit, Michigan. In 1987, Intel introduced the first CAN controller chips, and shortly thereafter by Philips. Released in 1991, the Mercedes-Benz W140 was the first production vehicle to feature a CAN-based multiplex wiring system. Bosch published several versions of the CAN specification and the latest are CAN 2.0 published in 1991 and CAN FD in 2012. https://www.can-cia.org/
EtherNet/IP: EtherNet/IP is an industrial network protocol that adapts the Common Industrial Protocol (CIP) to standard Ethernet. EtherNet/IP is one of the leading industrial protocols in the United States and widely used in a range of industries including factory, hybrid and process. The EtherNet/IP and CIP technologies are managed by ODVA, Inc., a global trade and standards development organization founded in 1995 with over 300 corporate members. EtherNet/IP performs at level session and above (level 5, 6 and 7) of the OSI model. CIP uses its object-oriented design to provide EtherNet/IP with the services and device profiles needed for real-time control applications and to promote consistent implementation of automation functions across products. EtherNet/IP adapts key elements of Ethernet’s standard capabilities and services to the CIP object model framework, such as the User Datagram Protocol (UDP), which EtherNet/IP uses to transport I/O messages. http://www.odva.org/
PowerLink: POWERLINK, also called Ethernet Powerlink, is a real-time protocol for standard Ethernet. It is an open protocol managed by the Ethernet POWERLINK Standardization Group (EPSG) and introduced by Austrian automation company B&R in 2001. The protocol application layer is based on CANopen and is one of the most widely used application protocols today. POWERLINK uses the same device description files as CANopen as well as the same object dictionaries and communication mechanisms, including process data objects (PDOs), service data objects (SDOs) and network management (NMT). As with CANopen, direct cross-traffic is also one of the essential features of POWERLINK. All CANopen applications and device profiles can be directly implemented in POWERLINK environments as well; the applications will not see a difference between the two protocols. For this reason, POWERLINK also is referred to as "CANopen over Ethernet" https://www.ethernet-powerlink.org/
Modbus: Modbus is a data communications protocol originally published by Modicon (now Schneider Electric) in 1979 for use with its PLCs. Modbus has become a de facto standard communication protocol and is now a commonly available means of connecting industrial electronic devices. Modbus, which is openly published and royalty-free, is popular in industrial environments.
The Modbus protocol uses character serial communication lines, Ethernet or the internet protocol suite as a transport layer. There are three flavors:
1. Modbus RTU: This is used on serial communication lines, using e.g., RS-232 or RS-485 as a carrier.
2. Modbus TCP: This encapsulates Modbus RTU request and response data packets in a TCP packet transmitted over standard Ethernet networks.
3. Modbus ASCI: Modbus ASCII is an older implementation that contains all elements of an RTU packet, but expressed entirely in printable ASCII characters. Modbus ASCII is considered deprecated, rarely used any more, and not included in the formal Modbus protocol specification.
Since April 2004, the Modbus Organization has managed the development and update of Modbus protocols, when Schneider Electric transferred rights to that organization. The Modbus Organization is an association of users and suppliers of Modbus compliant devices that advocates for the continued use of the technology. Modbus Organization, Inc. is a trade association for the promotion and development of Modbus protocol. http://www.modbus.org/
EtherCAT: EtherCAT (Ethernet for Control Automation Technology) is an Ethernet-based fieldbus system. The protocol is standardized in IEC 61158 and suitable for both hard and soft real-time computing requirements in automation technology. The goal during development of EtherCAT was to apply Ethernet for automation applications requiring short data update times (also called cycle times; ≤ 100 μs) with low communication jitter (for precise synchronization purposes; ≤ 1 μs) and reduced hardware costs. http://www.ethercat.org/
CC-Link: CC-Link IE. The CC-Link Open Automation Networks Family is a group of open industrial networks that enable devices from numerous manufacturers to communicate, and used in a wide variety of industrial automation applications at the machine, cell and line levels. http://www.cc-link.org/
Sercos III: This is the third generation of the Sercos interface, a standardized open digital interface for the communication between industrial controls, motion devices, input/output devices (I/O) and Ethernet nodes, such as PCs. Sercos III applies the hard real-time features of the Sercos interface to Ethernet. Work began on Sercos III in 2003, with vendors releasing first products supporting it in 2005. http://www.sercos.org/
IO-Link: IO-Link is the first standardized IO technology worldwide (IEC 61131-9) for the communication with sensors and actuators. The powerful point-to-point communication is based on the long established three-wire sensor and actuator connection without additional requirements regarding the cable material. IO-Link is no Fieldbus, but instead is the further development of the existing, tried-and-tested connection technology for sensors and actuators. https://io-link.com/en/
6.0 Methods to Organize and Store Manufacturing Data
A data repository is a centralized location to store and manage data of any type, including structured and unstructured data, and used for a variety of purposes, such as data storage, data backup, data analysis and data sharing. It offers organizations the ability to store and access their data quickly while maintaining organizational structure and security measures. The repository allows users to add new information, edit existing information, search for specific sets of information and categorize the sets according to custom criteria.
Both cloud-based and on-premise systems can host data repositories. Cloud-based repositories are favored by organizations because they reduce overhead costs, are easily scalable and provide quick access to up-to-date versions of the stored data. On-premise repositories offer organizations more control over their data but require greater investments in hardware infrastructure as well as IT personnel to maintain them.
There are several types of data repositories, including:
Time Series Databases/Historians: These databases specifically handle data streams representing information that continually changes with time that is either stored as values captured at regular intervals or when the value changes sufficiently. These repositories are most useful for capturing data that is the Continuous type, as described previously.
Relational databases: These are the most common type of database used by businesses today. These databases are highly structured and store data in tables and allow for the creation of relationships between different data elements. Most relational databases [add reference] use (or have the option to use) Structured Query Language (SQL) for querying and maintaining the database. Relational databases are fast, reliable, secure and easily scalable for larger datasets. The main drawback is that the structure of relational databases is very rigid and tends to be more expensive than other types of databases due to complexity and the level of maintenance required.
NoSQL Databases: These databases are designed to store and manage large amounts of unstructured and semi-structured data, such as documents, images and video. Unlike traditional relational databases, NoSQL databases use a variety of data models and do not use SQL to access and manipulate data. This makes them more flexible than SQL databases, but conversely adds complexity when extracting and using the data, since there is no inherent structure or query language. NoSQL databases often are used in situations where the data is too large or complex for efficient storage and management in a traditional relational database, or where there is a need to access and manipulate data in real-time.
Semantic/Graph Databases: These databases are semi-structured and fall somewhere in between SQL and unstructured NoSQL variants. Unlike a SQL database where the information schema is pre-defined by rigid table structures and key definitions, a graph database uses a simpler structure representing only the relationships between things, called nodes and edges. Nodes (the relationships) connect to edges (the things) to enable piece-meal modeling of information by the data itself. In this way, the schema is created on the fly as the data is captured, and grows flexibly as needed to support its intended purpose. Like other NoSQL types, there is no standardized query language available, but there are some commonly used multi-vendor tools that support data extraction, and some databases also provide APIs for this purpose. Graph databases are a good compromise between SQL and NoSQL by combining the best parts of both - inherent structure, but with the flexibility to constantly morph as needs grow or change. For more on graph databases and how they compare with Relational Databases, please refer to this article - https://www.freecodecamp.org/news/graph-database-vs-relational-database/. Somewhat independent of database type is how to architect information management. These generally fall into two camps - purpose-built and unconstrained. The most common variants are:
Data Warehouses: These are traditional purpose-built solutions https://www2.cs.sfu.ca/CourseCentral/459/han/papers/chaudhuri97.pdf that allow businesses to store structured data in a highly organized fashion. They are typically large and centralized databases used by organizations that need fast access to specific analytical insights from their data. Additionally, they offer strong governance features and scalability options, making them well suited for organizations with large complex data sets. The downside is that they can be expensive and require a significant amount of time and resources to maintain.
Data Mart: These are a subset of a data warehouse designed to support the reporting and analysis needs of a specific business unit or department. Data mart typically contains a subset of the data stored in the larger data warehouse, and tailored to meet the specific needs of the business unit or department that it serves.
Data Lakes: These are relatively new storage solutions that allow businesses to store large amounts of raw data without having to pre-process it first. This makes data lakes ideal for businesses that need to store large quantities of unstructured or semi-structured data without a pre-determined purpose for it. Data lakes are cost effective and easy to scale, but are more difficult to query because of the lack of structure and difficulty of enforcing data governance. They are flexible and future-proof, since there is no prerequisite schema. But for the same reason, they require additional software and/or translation effort before using the data in a practical or straightforward manner. The following link provides a comprehensive introduction and description of data lakes - https://www.pwc.com/us/en/technology-forecast/2014/cloud-computing/assets/pdf/pwc-technology-forecast-data-lakes.pdf.
Data Mesh: This improvement to the monolithic data lake handles storage, consumption and transformation of data in one centralized location, and supports domain-specific distributed data with each domain managing their own Extract, Transform and Load pipelines. The data mesh delivers a central virtual data source in real-time but leaves that data physically wherever each domain stores it. This architecture allows for better control in the presence of increasing volumes of data, even though it can lead to duplication of infrastructure. Also, since there are different uses of the same data within an organization and the data requires different transformations corresponding to these use cases, instead of having the load on a centralized platform - such as a data lake - the load is distributed in a data mesh, wherein the individual domains are responsible for handling the different use cases in a decentralized manner.
A subsequent article focusing on Information Models for Smart Manufacturing Applications will provide a more detailed description of data mesh.
AUTHORS:
1. Ananth Seshan
2. Madhu Gaganam
2. Jeff Winter
3. Stefan Zippel
4. Rick Slaugenhaupt
REVIEWERS:
1. Prachi Shrivastava
2. Conrad Leiva
3. Michael Ford
The next article in this series on manufacturing data will focus on organizing the data and the use of information models.
3 comments:
Very thorough and informative post.....my customers in the Mfg space will find this valuable.
Except for this:
"Data Mesh: This improvement to the monolithic data lake handles storage, consumption and transformation of data in one centralized location, and supports domain-specific distributed data with each domain managing their own Extract, Transform and Load pipelines."
For the most part, this is on point except that using ETL / ELT in order to manage Data in "one centralized location" is legacy thinking and a very poor approach. A much better (and more futureproof) method, is to virtualize that Data wherever it sits and leverage it in real time without "moving it to use it."
This eliminates Data duplication, increases speed to analysis and is much more cost effective over the legacy approach of thinking that Data needs to move before it becomes valuable. Plus, it builds trust in the Data because it hasn't been transformed or replicated. It's usable in its most raw form, possible.
The underlying capability of a Data Mesh is either Data Virtualization or Data Fabric. Not ETL or ELT.
If that is how companies are leveraging these new architectural patterns like a Data Mesh, they are simply faking it and it is not a Data Mesh. It's just a Datalake/Datawarehouse approach masquerading as a Data Mesh.
There are much better ways these days.
@Dave very good catch on Data Mesh topic. Can't believe we missed that. We will work on editing the article. Thanks for your Comment. We welcome more Comments on the topic and more collaborators on the next article on Information Modeling.
Looking forward to more thought leadership content from you and the next articles!
Post a Comment